
Self-supervised surround-view depth estimation enables dense, low-cost 3D perception with a 360° field of view from multiple minimally overlapping images. Yet, most existing methods suffer from depth estimates that are inconsistent across overlapping images. To address this limitation, we propose a novel geometry-guided method for calibrated, time-synchronized multi-camera rigs that predicts dense metric depth. Our approach targets two main sources of inconsistency: the limited receptive field in border regions of single-image depth estimation, and the difficulty of correspondence matching. We mitigate these two issues by extending the receptive field across views and restricting cross-view attention to a small neighborhood. To this end, we establish the neighborhood relationships between images by mapping the image-specific feature positions onto a shared cylinder. Based on the cylindrical positions, we apply an explicit spatial attention mechanism, with non-learned weighting, that aggregates features across images according to their distances on the cylinder. The modulated features are then decoded into a depth map for each view. Evaluated on the DDAD and nuScenes datasets, our method improves both cross-view depth consistency and overall depth accuracy compared with state-of-the-art approaches.

Exemplary 3D reconstructions, comparing our method to the state-of-the-art on nuScenes. It shows the reconstruction of the overlap regions of the front-right, back-right and the back camera.

Exemplary consistency error maps, computed using the metric described in Sec. 4.1 overlayed on the front-image, comparing our approach with state-of-the-art methods on DDAD. Our method maps overlapping regions from the two images to nearby 3D coordinates. In contrast, the other methods exhibit a higher inconsistency in these regions (green bounding boxes). (a) shows the combined relevant regions from the front-right and front-left images that overlap with the front image. Errors are visualized using the inferno colormap, ranging from black (low error) to yellow (high error).
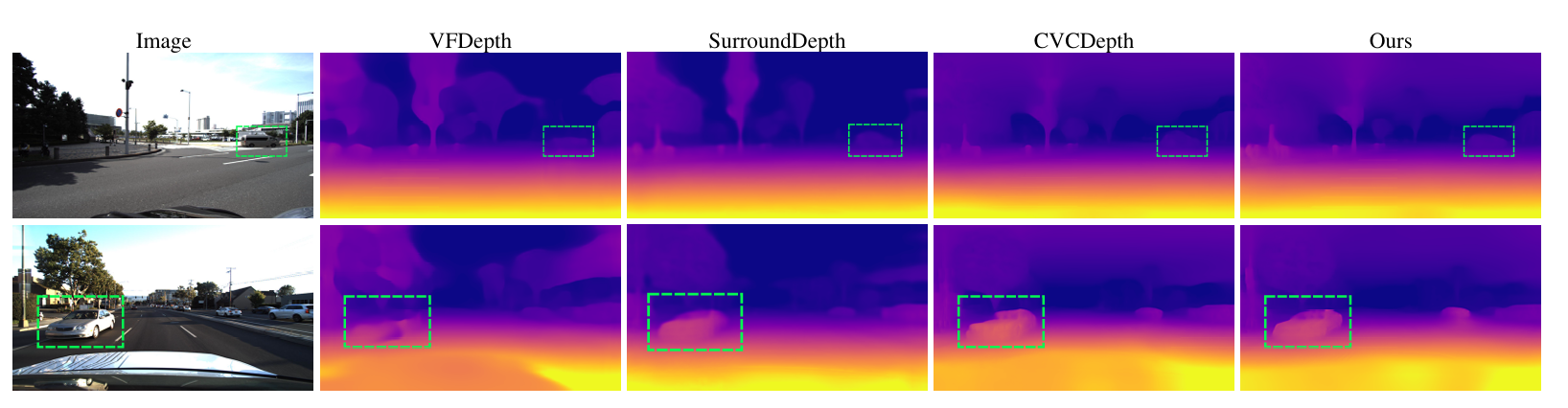
Comparison of depth maps predicted by our method and by state-of-the-art methods on DDAD. Our results show better preserved details and well-defined object boundaries (green bounding boxes).
@InProceedings{Abualhanud2026,
author = {Abualhanud, Samer and Grannemann, Christian and Mehltretter, Max},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops},
title = {CylinderDepth: Cylindrical Spatial Attention for Multi-View Consistent Self-Supervised Surround Depth Estimation},
year = {2026},
note = {Accepted for publication.}
}